Randomization units
Read time: 5 minutes
Last edited: Dec 12, 2024
Overview
This topic explains what randomization units are and how to use them in LaunchDarkly Experimentation.
An experiment's randomization unit is the context kind the experiment uses to assign traffic to each of its variations. For example, if you choose the user context kind as an experiment's randomization unit, then the experiment will divide contexts into the experiment's variations by individual users.
Randomization units in experiments
Before you begin an experiment, you must:
- choose an industry-standard randomization unit for the experiment,
- map the randomization unit to an appropriate context kind,
- map the context kind to the appropriate metrics, then
- add the randomization unit to the experiment.
These steps are explained below.
Industry standard randomization units
There are six industry-standard randomization units that you can use in Experimentation:
- user
- user-time
- guest
- guest-time
- organization
- request
LaunchDarkly limits experiments to randomizing by these six industry-standard units because other units might result in invalid results. If you have a context kind that doesn't logically map to one of these industry-standard units, it may not be appropriate to use as a randomization unit. For examples of common context kind mapping, read the table in Map randomization units to context kinds.
For example, if you tried to use "country" as a randomization unit, your experiment would serve the same variation to everyone in a particular country. If your experiment had end users in the United States, Mexico, and Canada, the experiment might serve variation A to all end users in the United States and Canada, and variation B to all end users in Mexico. This could result in significantly uneven numbers of end users in each variation, and each variation would not include a random sampling of end users. At the end of the experiment, there would be no way to tell if variation A or B performed better in any given country.
Instead, if you wanted to view results by country, you could filter your results by context attribute. To learn more, read Filtering experiment results.
Map randomization units to context kinds
The built-in user context kind is automatically mapped to the user standard randomization unit. If you have created additional context kinds you want to use in experiments, then you must first map them to one of the standard randomization units. Multiple context kinds can be mapped to the same standard randomization unit. To learn how, read Creating context kinds.
Here is an example of mapping a new context kind of "customer" to the randomization unit "user":
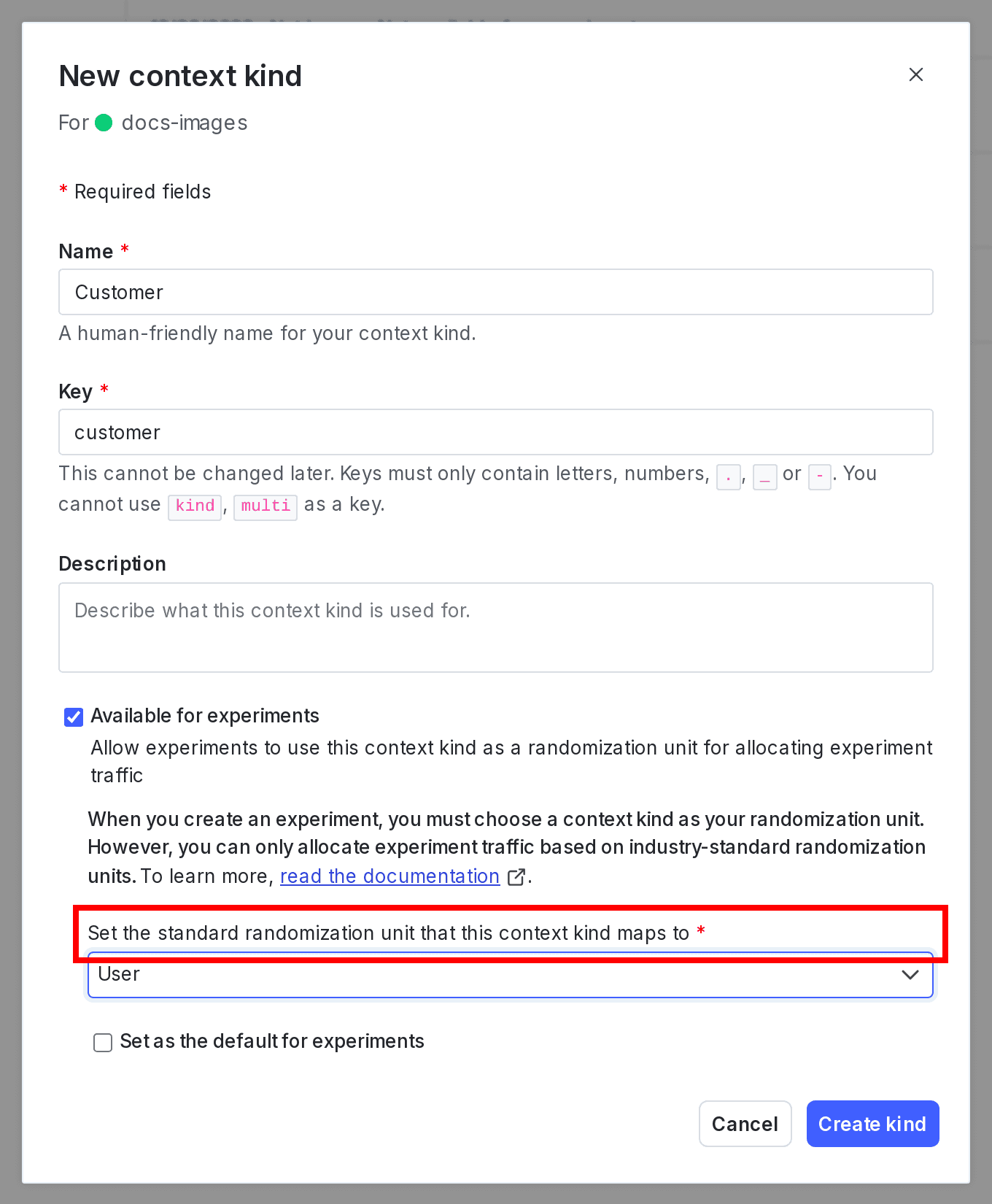
This table includes the industry-standard randomization units and example context kinds that might be associated with them:
| Standard randomization unit | Example context kind mappings | Description |
|---|---|---|
| User | user, member, customer | For each person that encounters your feature, randomly choose a variation for that particular person |
| User-Time | user+hour-of-day, user+day-of-weekTakes the form of a composite key of user-key and time-at-some-granularity | For each person that encounters your feature at a particular time of day or on a particular day of the week, randomly choose a variation for that person/time combination |
| Guest | device, cookie, session, logged-out user, guest, non-authorized user | For each non-logged-in person that encounters your feature, randomly choose a variation for that particular guest |
| Guest-time | guest+hour-of-day, guest+day-of-weekTakes the form of a composite key of guest-key and time-at-some-granularity | For each non-logged-in person that encounters your feature at a particular time of day or on a particular day of the week, randomly choose a variation for that guest/time combination |
| Organization | organization, company, business | For each organization that encounters your feature, randomly choose a variation for that organization |
| Request | HTTP request, operation, transaction, interaction | For each particular action that someone performs on your platform, randomly choose a variation for that particular request, operation, or action |
If you're unsure of which randomization unit to map to your context kind, start a Support ticket for help.
Map randomization units to metrics
When you create a metric, you must map the new metric to a context kind you have marked as available for experiments:
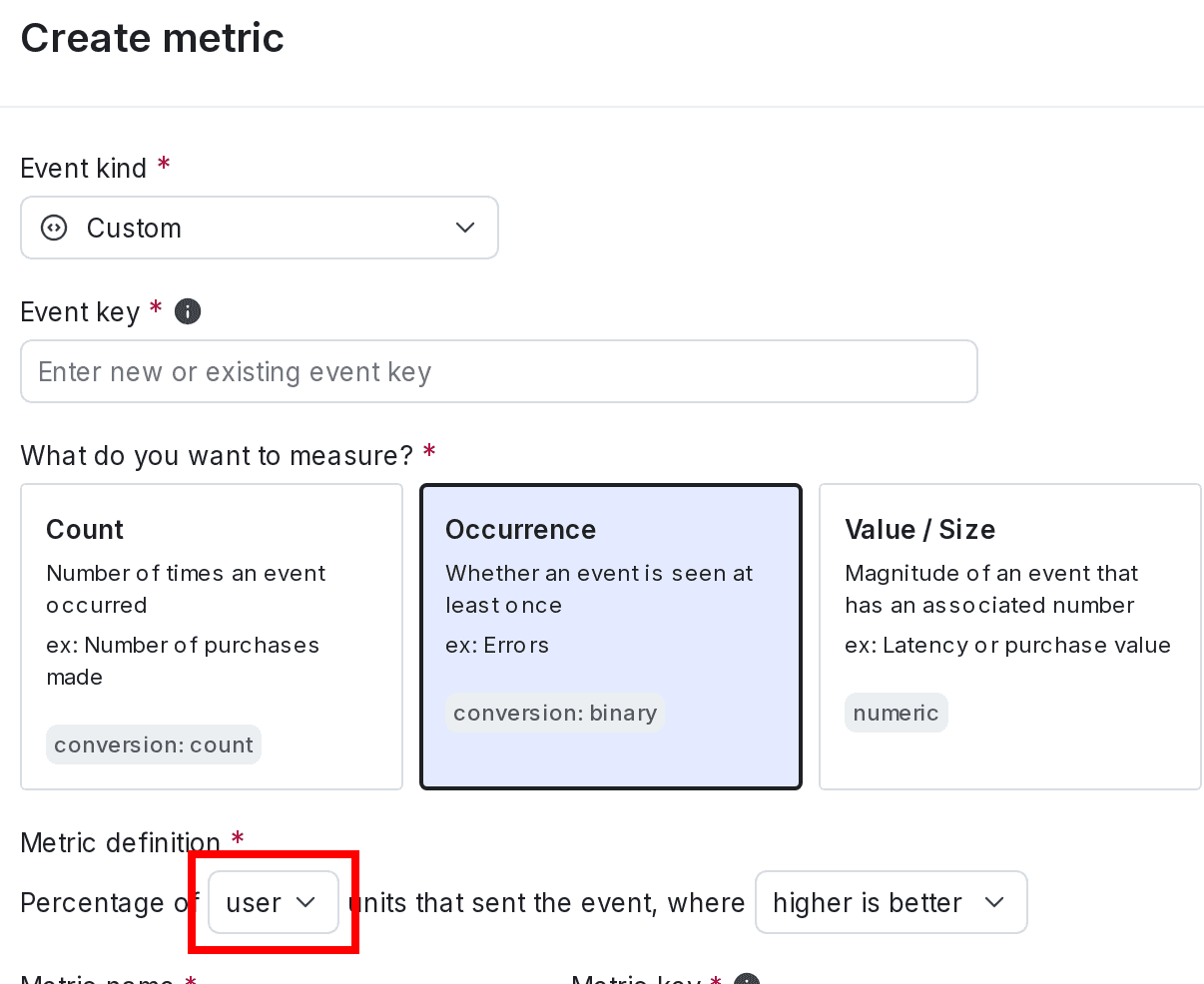
This context kind determines which randomization units the metric is compatible with. To learn more, read Metrics.
Choose randomization units for experiments
Finally, when you create an experiment, you will choose a randomization unit that determines both:
- which context kind the experiment will allocate traffic to different variations by, and
- which metrics you can use in the experiment.
In this example, the experiment has a randomization unit of user. It is compatible with the chosen metric, because the metric can measure events from user context kinds.

Using randomization units with multi-contexts
Expand the example below to see how you can use different randomization units within the same experiment.
Using randomization units with multi-contexts
Imagine users Anne and Jesse both work for the same organization, and are part of an experiment comparing two variations. Both Anne and Jesse are each part of a different multi-context, with different user keys but the same organization key.
Here is what their multi-contexts would look like, though each SDK sends context data to LaunchDarkly in a slightly different format:
There are two ways you could randomize the multi-contexts in an experiment:
- if you randomize by
user, Anna could be assigned to one variation, and Jesse could be assigned to the other variation because they have different user keys - if you randomize by
organization, Anna and Jesse will both always be assigned to the same variation because they share the same organization key