Frequentist experiment results
Read time: 6 minutes
Last edited: Dec 10, 2024
Overview
This topic explains how to read and use the Latest results tab of a frequentist experiment.
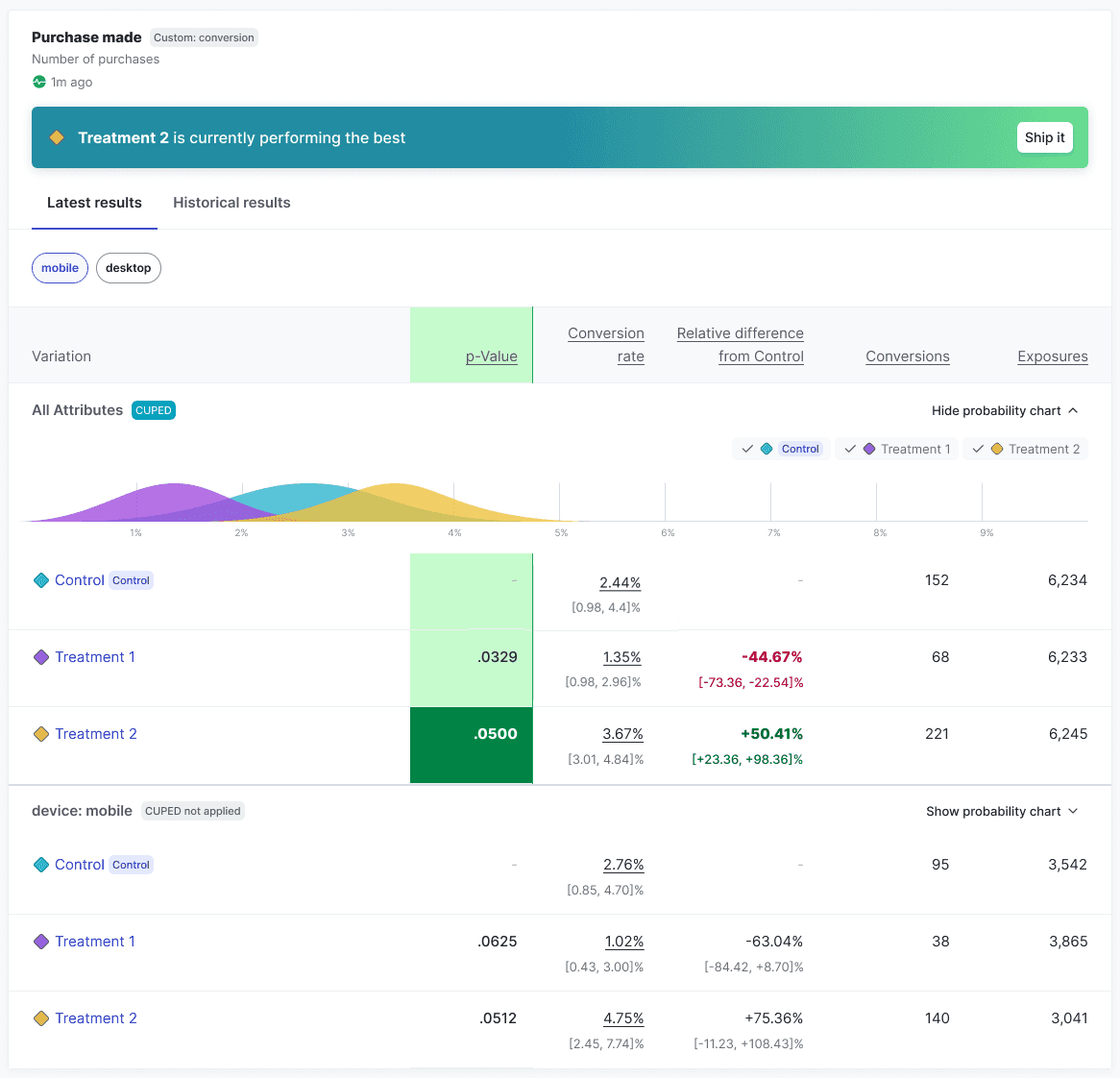
Probability charts
An experiment's probability chart provides a visual representation of the performance of each variation tested in the experiment for the primary metric:
Each experiment's probability chart is unique, and how you interpret the results depends on what metric you're measuring and the hypothesis of your experiment. The following sections provide general information about the x-axis and the y-axis to help you interpret experiment results.
To hide any of the variations from the probability chart, uncheck the box next to the variation's name:
Expand information about the x-axis
The horizontal x-axis displays the unit of the primary metric included in the experiment. For example, if the metric is measuring revenue, the unit might be dollars, or if the metric is measuring website latency, the unit might be milliseconds.
If the unit you're measuring on the x-axis is something you want to increase, such as revenue, account sign ups, and so on, then the farther to the right the curve is, the better. The variation with the curve farthest to the right means the unit the metric is measuring is highest for that variation.
If the unit you're measuring on the x-axis is something you want to decrease, such as website latency, then the farther to the left the curve is, the better. The variation with the curve farthest to the left means the unit the metric is measuring is lowest for that variation.
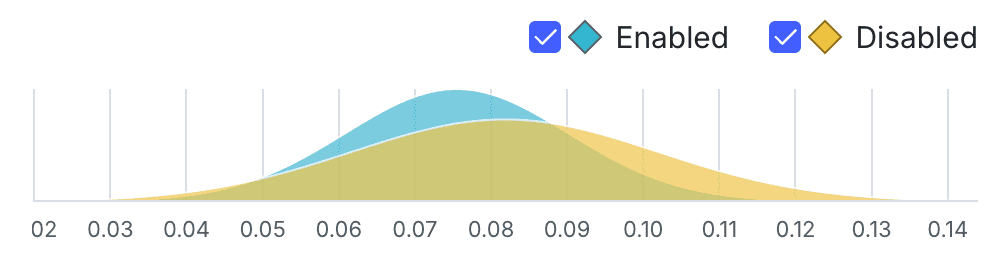
How wide a curve is on the x-axis determines the credible interval. Narrower curves mean the results of the variation fall within a smaller range of values, so you can be more confident in the likely results of that variation's performance.
In the example below, the green variation has a more precise credible interval than the purple variation:
Expand information about the y-axis
The vertical y-axis measures probability. You can determine how probable it is that the metric will equal the number on the x-axis by how high the curve is.
In the example above, the green variation has a high probability that the metric will measure 0.4 for any given context. In other words, if someone encounters the green variation, there's a high probability that the metric will measure 0.4 for that person.
P-value
Probability value, or p-value, is a measure of how likely it is that any difference observed between a treatment variation and the control variation is due to random chance, rather than an actual difference in performance between the two variations. The idea that there is no actual difference between two groups is called the null hypothesis.
The p-value helps determine whether the null hypothesis is true for a given set of variations:
- A small p-value, typically less than or equal to 0.05, suggests that the observed data is due to actual differences in performance between the treatment variation and the control variation. A small p-value is evidence that the null hypothesis is not true, that is, there is evidence that real differences exist.
- A large p-value, typically more than 0.05, suggests that the observed data is not due to actual differences in performance between the treatment variation and the control variation. A large p-value means there is not enough evidence that the null hypothesis is not true, that is, there is not enough evidence that real differences exist.
Funnel optimization experiments
In funnel optimization experiments, LaunchDarkly calculates the p-value for each step in the funnel, but the final metric in the funnel is the metric you should use to decide the winning variation for the experiment as a whole.
LaunchDarkly includes all end users that reach the last step in a funnel in the experiment's winning variation calculations, even if an end user skipped some steps in the funnel. For example, if your funnel metric group has four steps, and an end user takes step 1, skips step 2, then takes steps 3 and 4, the experiment still considers the end user to have completed the funnel and includes them in the calculations for the winning variation.
Conversion rate
The conversion rate displays for all conversion metrics. Examples of conversions include clicking on a button, or entering information into a form.
Conversion metrics can be one of two types: count or binary.
Count conversion metrics
The value for each unit in a count conversion metric can be any positive value. The value equals the number of times the conversion occurred. For example, a value of 3 means the user clicked on a button three times.
The aggregated statistic for count conversion metrics is the average number of conversions across all units in the metric. For example, the average number of times users clicked on a button.
Count conversion metrics include:
- Clicked or tapped metrics using the Count option
- Custom conversion count metrics
- Page viewed metrics using the Count option
Binary conversion metrics
The value for each unit in a binary conversion metric can be either 1 or 0. A value of 1 means the conversion occurred, such as a user viewing a web page, or submitting a form. A value of 0 means no conversion occurred.
The aggregated statistic for binary conversion metrics is the percentage of units with at least one conversion. For example, the percentage of users who clicked at least once.
Binary conversion metrics include:
- Clicked or tapped metrics using the Occurrence option
- Custom conversion binary metrics
- Page viewed metrics using the Occurrence option
For funnel optimization experiments, the conversion rate includes all end users who completed the step, even if they didn't complete a previous step in the funnel. LaunchDarkly calculates the conversion rate for each step in the funnel by dividing the number of end users who completed that step by the total number of end users who started the funnel. LaunchDarkly considers all end users in the experiment for whom the SDK has sent a flag evaluation event as having started the funnel.
Relative difference from Control
For conversion metrics, the relative difference from control is the difference between the treatment variation's conversion rate and the control variation's conversion rate. To learn about viewing the relative difference from control over time, read Historical results for frequentist experiments.
Mean
The mean displays only for numeric metrics. To learn more, read Custom numeric metrics.
The mean is the variation's average numeric value that you should expect in this experiment, based on the data collected so far. To learn about viewing the mean over time, read Historical results for frequentist experiments.
Conversions or Total value
Depending on the metric type, the Latest results tab displays one of the following two columns containing the sum of unit values for the numerator of the metric:
- Conversions: the total number of conversions for a conversion metric
- Total value: the total value for a numeric metric
The raw conversion rate is the number of conversions divided by the number of exposures. The raw mean is the total value divided by the number of exposures.
Exposures
The exposures column displays the total number of contexts measured by the metric.
You can also use the REST API: Get experiment results
To learn more about troubleshooting if your experiment hasn't received any metric events, read Experimentation Results page status: "This metric has never received an event for this iteration".